
Переклад статті Learnings from two years of using AI tools for software engineering, Jun 2025
Здається, що GenAI швидко змінює сферу розробки програмного забезпечення: спочатку з’явилося розумніше автозаповнення, а тепер є ще більше інструментів, які використовують багато інженерів. Але які є практичні підходи до використання цих інструментів?
Щоб дізнатися більше, я звернувся до Біргітти Бекелер, видатного інженера в Thoughtworks, яка останні два роки повністю присвятила себе розв’язанню цього питання. Вона все ще пише продакшин код у Thoughtworks, але її основна увага зосереджена на розвитку експертизи в галузі постачання програмного забезпечення за допомогою штучного інтелекту.
Щоб бути в курсі останніх розробок, Біргітта спілкується з колегами з Thoughtworks, клієнтами та іншими фахівцями галузі, а також використовує різні AI інструменти. Вона випробовує інструменти та з’ясовує, як вони вписуються в її робочий процес. Сьогодні Біргітта розповість нам про те, чого вона навчилася за останні два роки роботи з інструментами штучного інтелекту:
- Еволюція від «автозаповнення на стероїдах» до AI агентів. Від перших днів автозаповнення, через чати зі штучним інтелектом та інтеграцію IDE, до кардинальної зміни на користь агентів.
- Робота зі штучним інтелектом: практична ментальна модель вашого «AI-колеги по команді», обережність щодо когнітивних упереджень, коли GenAI може «маніпулювати» вами, та нові робочі процеси зі штучним інтелектом.
- Вплив на ефективність команди. Асистенти з кодування ШІ збільшують швидкість постачання програмного забезпечення, хоча точно виміряти, наскільки саме, складно. Без ретельного нагляду вплив на якість може бути негативним. Швидке впровадження цих інструментів, швидше за все, вплине на динаміку команди.
- Майбутнє. LLM — це не наступні компілятори: це щось інше, майбутнє кодування ШІ розподілено нерівномірно, і ми будемо брати на себе технічний борг, поки з’ясовуємо, як правильно використовувати ці інструменти ШІ.
Щоб дізнатися більше, ознайомтеся з додатковими думками Біргітти в колекції «Exploring Generative AI» на веб-сайті її колеги Мартіна Фаулера.
Зверніть увагу, що терміни «ШІ», «генеративний ШІ» та «LLM» в цій статті вживаються як синоніми.
У липні 2023 року, в компанії Thoughtworks вирішила запровадити посаду штатного експерта з “розробки (delivery) програмного забезпечення за допомогою штучного інтелекту». Це було в той час, коли все більш очевидним ставав величезний вплив генеративного штучного інтелекту на розробку програмного забезпечення, і мені пощастило опинитися в потрібному місці в потрібний час, маючи відповідну кваліфікацію для цієї посади. І з того часу я не перестаю вчитися.
Я вважаю себе експертом у галузі ефективної розробки програмного забезпечення, який застосовує генеративну штучну інтелігенцію в цій галузі. У рамках цієї посади я спілкуюся з колегами з Thoughtworks, клієнтами та іншими фахівцями галузі. Я сам використовую ці інструменти і намагаюся бути в курсі останніх розробок, а також регулярно пишу і розповідаю про свої висновки та досвід.
Ця стаття є підсумком моїх висновків, досвіду та контенту за останні 2 роки.
1. Еволюція від “автокомпліту на стероїдах” до AI агентів
Інструменти кодування на основі штучного інтелекту розвиваються з шаленою швидкістю, тому дуже важко бути в курсі останніх розробок. Тому розробники не тільки стикаються з проблемою адаптації до природи генеративного штучного інтелекту, але й з додатковою перешкодою: сформувавши думку про інструменти або встановивши робочі процеси, вони мусять постійно пристосовуватися до нових розробок. Деякі процвітають у цьому середовищі, а інші вважають його фруструючим.
Тож давайте почнемо з короткого огляду того, як розвивалися помічники з кодування на основі штучного інтелекту за останні два роки. Все почалося з вдосконаленого автозаповнення, а сьогодні ми маємо цілу низку агентів з кодування, з яких можна вибирати.
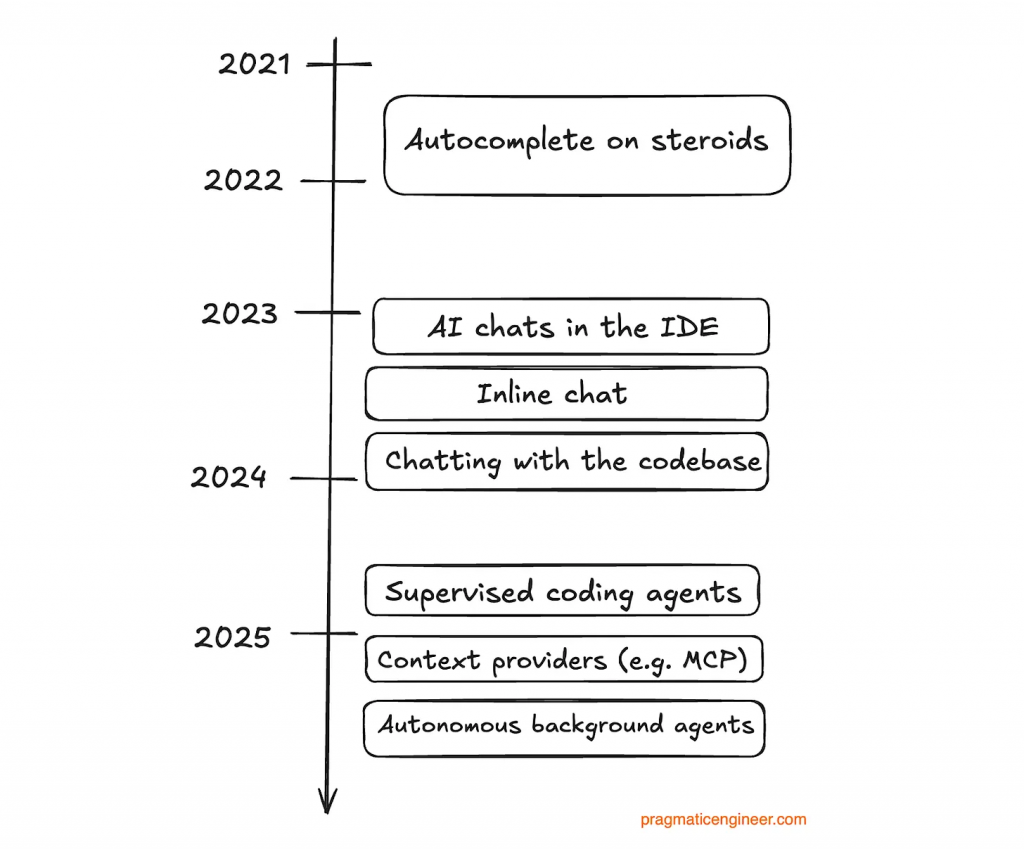
Початок: автозаповнення на стероїдах
Перший крок у напрямку допомоги в кодуванні за допомогою штучного інтелекту здавався вдосконаленою версією вже відомої нам функції автодоповнення, але на новому рівні. Наскільки мені відомо, Tabnine був першим відомим продуктом, який запропонував цю функцію, приблизно в 2019 році. GitHub Copilot був вперше випущений у альфа версії у 2021 році. Це був перехід від прогнозів, заснованих на абстрактних синтаксичних деревах і відомих шаблонах рефакторингу та реалізації, до механізму пропозицій, який набагато краще адаптується до нашого поточного контексту та логіки, але також є менш детермінованим і більш випадковим. Реакції розробників варіювалися від захоплення до зневажливого «Я залишуся при своїх надійних функціях та скороченнях IDE, дякую».
Вже тоді я вважав це корисним засобом підвищення продуктивності й досить швидко звик, особливо з мовами, з якими я був менш знайомий. Однак, як і багато інших, я незабаром виявив реальність «втоми від перегляду», яка змушує деяких розробників вимикати помічника і повністю зосередитися на створенні коду, а не на його перегляді.
AI чати в IDE
Сьогодні це здається неймовірним, але колись у помічників не було функції чату. Пригадую, як у липні 2023 року я оголосив у корпоративному чаті, що наші ліцензії GitHub Copilot нарешті отримали функцію чату: через 24 хвилини хтось написав, що попросив Copilot пояснити скрипт оболонки за допомогою метафор із «Зоряних воєн». З точки зору досвіду розробника, це було дуже важливо — мати можливість задавати питання безпосередньо в IDE, не переходячи в браузер і не переглядаючи велику кількість контенту, щоб знайти відповідну інформацію для моєї ситуації.
І це було не просто задавання прямих питань, наприклад, чи є статичні функції в Python; ми також почали використовувати їх для пояснення коду та простого налагодження. Я пам’ятаю, як деякий час боровся з логікою, перш ніж асистент пояснив, що дві мої змінні були названі неправильно, через що я весь час неправильно розумів код.
У цей момент галюцинації стали ще більш актуальною темою для обговорення, разом із порівняннями зі StackOverflow, який почав спостерігати перший спад трафіку.
Розширена інтеграція із IDE
Поступово інструменти ШІ також стали більш інтегрованими в існуючу функціональність IDE: ШІ почав з’являтися в меню «швидкого виправлення», а інтеграція з терміналом IDE покращилася. Наприкінці 2023 року я нарешті перестав використовувати підказки у вигляді коментарів до коду; натомість я почав використовувати невеликий вбудований редактор-чат, щоб давати швидкі підказки прямо в тому місці, де був мій код.
Інтеграція DE — одна з причин, чому я віддаю перевагу використання помічників кодування IDE над термінальними. IDE створені для розуміння, навігації та зміни коду, і поєднання їх з LLM на основі токенів є дійсно потужним. Я вірю, що існує ще багато невикористаного потенціалу інтеграції, і з нетерпінням чекаю, коли мій агент отримає доступ до функцій налагодження або рефакторингу.
Спілкування з кодовою базою (Chatting with the Codebase)
Ключовим моментом для AI-асистентів є контекст того, над чим вони працюють, тому їх інтеграція з кодовою базою в цілому стала наступним великим кроком, який почав реалізовуватися приблизно восени 2023 року. Можливість поставити питання про кодову базу особливо корисна при роботі з незнайомою базою, і я вважаю дуже корисним можливість ставити такі питання, як «де реалізована валідація X» або «як ми фільтруємо?». Навіть на початку розвитку цих функцій я виявив, що вони частіше за все вказували мені правильний напрямок і надавали додаткову цінність порівняно з текстовим пошуком. З того часу розуміння кодової бази значно покращилося.
Ефективність реалізації цього пошуку в коді все ще є фактором, що відрізняє різні програми-помічники для кодування. Підходи варіюються від векторних індексів, таких як Cursor і Windsurf, до абстрактного синтаксису та текстового пошуку на основі дерева файлів, такого як Cline, і до складних пошукових систем коду, таких як Sourcegraph Cody.
Джерело контексту
Однак кодова база — це не весь контекст, що існує; є багато інших джерел даних, які можуть надати корисний контекст для AI-асистента. До асистентів було інтегровано більше джерел контексту, щоб надати розробникам більший контроль над інформацією, яку бачить AI-асистент. Розробники могли вказати на локальний набір змін, вихідні дані терміналу, адреси веб-сайтів, довідкову документацію і навіть перші випадки інтеграції тікетів із JIRA.
Перші ознаки необхідності створення екосистеми з’явилися, коли GitHub оголосив про GitHub Copilot Extensions у травні 2024 року — спосіб для постачальників інтегрувати постачальників контексту. Сьогодні MCP (Model Context Protocol) прискорив розвиток екосистеми постачальників контексту та зайняв цю нішу.
Еволюція моделей
Паралельно з усіма цими функціями інструментів еволюціонували і моделі. Ця сфера є особливо складною для відстеження, оскільки важко отримати об’єктивні показники ефективності моделі для кодування. Короткий виклад того, на якому етапі знаходиться еволюція моделей на даний момент, полягає в тому, що, хоча існує кілька хороших кандидатів, серія Claude Sonnet від Anthropic явно стала незмінним фаворитом для завдань кодування. На сьогодні це моя «розумна стандартна» рекомендація. Використана модель, безумовно, важлива, але я вважаю, що все ще недооцінюється велика роль функцій та інтегрованих інструментів, особливо коли моделі поєднуються з інструментами, які розуміють код і тому можуть доповнювати суто токенізоване розуміння речей великою мовною моделлю (LLM).
Агентський прорив
Нинішній рубіж й, мабуть, найбільша зміна на сьогоднішній день – це поява агентного кодування. Наразі я поділяю агенти кодування на дві групи:
Агенти кодування під наглядом: інтерактивні чат-агенти, які керуються та управляються розробником. Створюють код локально, в IDE.
Інструменти: першим інструментом такого типу, який я побачив, був Aider, а його історія в git починається ще в травні 2023 року. Cline існує з липня 2024 року, агентні режими в Cursor і Windsurf з’явилися приблизно в листопаді 2024 року, а GitHub Copilot Coding Agent з’явився пізніше, в травні 2025 року. Claude Code і різні форки Cline також набули великої популярності в першій половині 2025 року.
Автономні агенти кодування у бекграунді: консольні агенти, які відправляються для автономної роботи над цілим завданням. Код створюється у віддаленому середовищі, запущеному виключно для цього агента, і в результаті розробник отримує PR (Pull Request). Деякі з них також можна запускати локально.
Інструменти: першим з них, який привернув до себе багато уваги, був Devin, про який було гучно оголошено в березні 2024 року, а незабаром після цього в Інтернеті розгорілася суперечка. У грудні 2024 року було випущено загальнодоступну версію. Хоча були й інші подібні спроби, зокрема відкритий проект під назвою «OpenDevin», який швидко довелося перейменувати на «OpenHands», фонові агенти нещодавно отримали новий імпульс завдяки випуску фонових агентів OpenAI Codex, Google Jules і Cursor.
Агенти кодування розширюють обсяг завдань, над якими можна співпрацювати з AI, до більшого циклу вирішення проблем. Це головним чином зумовлено посиленням автоматизації та інтеграцією з такими інструментами, як виконання команд терміналу або веб-пошук. Уявіть будь-який інструмент, який використовують розробники у своєму робочому процесі кодування, і як його інтеграція могла б покращити можливості агента кодування. Наразі MCP є каталізатором цієї екосистеми інтеграцій.
Ось приклад циклу вирішення проблеми:
- «Я отримую це повідомлення про помилку, допоможіть мені усунути її: …»
- Агент проводить веб-дослідження, знаходить щось у документації бібліотеки та деякі обговорення проблеми на GitHub.
- Додає залежність бібліотеки патчів до проекту.
- Запускає npm install, щоб встановити нову залежність.
- Додає необхідний код до проекту.
- Перезапускає додаток.
- Бачить повідомлення про помилку.
- Намагається виправити код на основі повідомлення про помилку.
- Знову перезапускає додаток.
- ...У випадку із контрольованим агентом людина стежить за його роботою і втручається, коли це необхідно. Таке стеження може полягати в перегляді міркувань агента, щоб переконатися, що він рухається в правильному напрямку, перегляді коду, перериванні та відкоті, відповідях на запитання агента або затвердженні виконання термінальних команд.
Багато людей познайомилися з режимами агентів під наглядом через мем «vibe coding» на початку лютого 2025 року. Хоча vibe coding за визначенням є режимом, в якому людина не перевіряє код, я все одно вважаю його належним до цієї категорії під наглядом, оскільки людина постійно дивиться на результат роботи програми та надає агенту зворотний зв’язок.
Автономні фонові агенти призначені для самостійної роботи над завданням, і людина дивиться на результат тільки після того, як агент закінчив роботу. Результатом може бути локальний комміт або pull request в репозиторій. Я ще не бачив, щоб вони працювали над чимось більшим, ніж невеликі прості завдання, але, ймовірно, вони займуть своє місце в нашому інструментальному ланцюжку, коли дозріють.
У цій статті ми розглядаємо агенти під наглядом. Автономні фонові агенти ще перебувають на початковій стадії розвитку і мають багато недоліків, які потрібно виправити. Нижче я використовую термін «кодуючі агенти» як синонім терміна «агенти під наглядом».
Робота із AI
Генеративна ШІ — це ціль що швидко рухається, тому способи роботи постійно адаптуються до нових розробок. Однак є деякі «вічні» принципи та способи роботи, які я застосовую сьогодні.
Перш за все, для ефективної роботи з GenAI необхідна чітка зміна мислення. Етан Молік, професор Уортонської школи бізнесу, дослідник у галузі ШІ, ще на початку зробив зауваження, що «ШІ — це жахливе програмне забезпечення». Це дійсно вразило мене: інструменти генеративного ШІ не схожі на будь-яке інше програмне забезпечення. Щоб ефективно їх використовувати, необхідно адаптуватися до їхньої природи та прийняти її. Ця зміна є особливо складною для інженерів-програмістів, які звикли до побудови детермінованої автоматизації. Неприємно та незручно, що ці інструменти іноді працюють, а іноді — ні.
Тому перше, що потрібно зробити — це змінити мислення, щоб стати ефективною людиною в робочому процесі.
Когнітивний зсув: ментальна модель AI співробітника
Для мене корисним кроком було уявити мого AI-помічника-розробника у вигляді якогось персонажу, антропоморфізувати його настільки, щоб відкалібрувати свої очікування (натхненний Етаном Молліком і його книгою «Co-Intelligence»). Для кожного колеги по команді існують ментальні моделі, які використовуються неявним чином при прийнятті рішення довіряти їхній роботі та вкладу. До думки та порад людини, яка має великий досвід у роботі з бекендом та інфраструктурою, швидше за все, довірятимуть, але все одно може бути розумно перевірити, коли вона створює свій перший React Hook.
Ось персонаж, якого я вибрав для AI-асистентів:
- Готовий допомогти
- Упертий, іноді з короткою пам’яттю
- Дуже начитаний, але недосвідчений
- Занадто впевнений у собі

Ця ментальна модель допомогла мені розвинути інтуїцію щодо того, коли звертатися до GenAI, коли більше довіряти її результатам, а коли менше. Я очікую ентузіазму та допомоги, а також доступу до актуальної інформації через веб-пошук. Але я все одно повинен проявляти розсудливість, враховувати контекст і залишатися остаточним авторитетом.
Остерігайтесь упереджень
Робота з генеративним ШІ є сприятливим ґрунтом для виникнення низки когнітивних упереджень, які можуть підірвати здатність до об’єктивної оцінки. Я вважаю це найцікавішою рисою GenAI: наскільки маніпулятивною є ця технологія.
Ось лише кілька прикладів потенційних когнітивних упереджень:
Упередження автоматизації відображає нашу схильність віддавати перевагу пропозиціям автоматизованих систем, ігноруючи суперечливу інформацію, навіть якщо ця інформація є правильною. Після того, як ви досягли успіху з кодом, згенерованим штучним інтелектом, природно почати надмірно довіряти системі. Упевнений тон і досконалий результат можуть змусити нас менше сумніватися в її рекомендаціях, навіть якщо досвід підказує інший підхід.
Ефект фреймінгу підсилює вплив позитивних, впевнених формулювань відповідей LLM. Наприклад, якщо ШІ пропонує, що певний підхід є «найкращою практикою», ми, швидше за все, сприймемо це за чисту монету і приймемо його, не враховуючи контекстні фактори.
Ефект закріплення може спрацювати, коли ШІ пропонує рішення, перш ніж ми про нього подумали. Після перегляду пропозицій ШІ нам може бути складніше творчо підійти до пошуку альтернативних рішень. Підхід ШІ стає нашою ментальною відправною точкою, що потенційно обмежує наше дослідження кращих альтернатив. З іншого боку, ШІ також може допомогти нам зменшити упередження закріплення, наприклад, коли допомагає модернізувати існуюче рішення, до якого ми вже прив’язані.
І нарешті, під час кодування за допомогою ШІ також працює версія помилки втрачених зусиль. Менше людських зусиль, вкладених у написання коду, повинно полегшити відмову від коду, який не працює. Однак я помітив, що надто прив’язався до великих фрагментів коду, згенерованого ШІ, які я волів би виправити, а не скасувати. Уявна економія часу створює психологічну інвестицію, яка може змусити людину не бажати відмовлятися від рішень, згенерованих ШІ, навіть якщо вони не є оптимальними.
Загальні принципи роботи
Коли ви морально підготувалися і налаштували себе не піддаватися упередженням, ось кілька загальних принципів, які я вважаю практичними для ефективного використання AI-асистентів.
Подумайте про цикли зворотного зв’язку. Як ви можете дізнатися, що AI виконала вказівки, і чи можна це швидко перевірити, а також зменшити втому від перегляду? Якщо це невелика зміна, чи пишете ви модульний тест, чи дозволяєте AI створити його і використовуєте його як основний пункт перегляду? Якщо це велика зміна, які доступні тести є надійними: інтеграційний тест, end-to-end test або просто перевірити вручну? Крім функціональності, чи є у вас методи швидкої перевірки коду: плагін статичного аналізу коду в IDE, пре-комміт-хук, TechLead для перевірки PR? Розумно знати всі варіанти і замислюватися над циклом зворотного зв’язку, працюючи над завданням з ШІ.
Знайте, коли зупинитися. Коли я відчуваю, що втрачаю контроль над рішенням і не дуже розумію, що відбувається, я повертаюся назад: або до всього набору локальних змін, або до попередньої контрольної точки — це функція, яку підтримують більшість помічників з кодування. Потім я розмірковую над тим, як підійти до завдання краще, наприклад, як поліпшити свої підказки, розбити завдання на менші кроки або вдатися до «ручного кодування», тобто написати код самостійно з нуля.
Знайте своїх джерела контексту та інструменти з якими працюєте. Чи має інструмент доступ до Інтернету, чи він покладається виключно на свої навчальні дані, який доступ він має до вашої кодової бази, чи він шукає її автоматично, чи ви повинні надавати явні посилання, які інші постачальники контексту та сервери MCP доступні та корисні? Знання можливостей та доступу інструменту важливе для вибору правильного інструменту для роботи, а також для коригування очікувань та рівня довіри. Ви також повинні знати, до яких даних має доступ агент і куди вони надсилаються, щоб розуміти ризики для процесу розробки та відповідально користуватися цим потужним інструментом.
Нові робочі процеси з агентами
До появи AI-агентів для розробки робочий процес програмування за допомогою AI-асистентів був відносно близьким до того, як зазвичай працюють інженери, 1–50 рядків коду за раз. AI супроводжувала нас і допомагала нам крок за кроком. Це змінилося з появою AI-агентів, які не тільки збільшують обсяг завдань, над якими потрібно працювати, але й обсяг необхідного огляду коду та контекстної інформації.
Нижче наведено основні рекомендації, які я зараз даю для роботи з агентами. Слід зазначити, що всі ці рекомендації є способами підвищення ймовірності успіху, але, як завжди у випадку з генеративним штучним інтелектом, гарантій немає, і його ефективність залежить від завдання та контексту.
Використовуйте власні інструкції. Власні інструкції — або «custom rules», як їх називають деякі інструменти — це чудовий спосіб підтримувати загальні інструкції для ШІ. Вони подібні до конфігурації AI помічника на природній мові і можуть містити інструкції щодо стилю та конвенцій кодування, технічного стеку, домену або просто заходів щодо усунення типових помилок, яких припускається ШІ.
Спочатку плануйте (за допомогою ШІ). Хоч як би привабливо звучало просто кинути агенту одне речення, а потім чарівним чином перетворити його на кілька змін в коді в більшій базі коду, зазвичай це не працює. Розбиття роботи на менші завдання не тільки полегшує агенту виконання правильних змін невеликими кроками, але й дає людині можливість переглянути спосіб розв’язання задачі, в якому рухається ШІ, і, за потреби, виправити його на ранній стадії.
Завдання мають бути невеликими. На етапі планування роботу слід розбити на невеликі завдання. Хоча моделі технічно мають дедалі більші контекстні вікна, це не обов’язково означає, що вони можуть добре обробляти весь контекст у довгій кодувальній розмові або що вони можуть зосередитися на найважливіших речах у цьому довгому контексті. Набагато ефективніше часто починати нові розмови і не дозволяти контексту ставати занадто великим, оскільки це зазвичай погіршує продуктивність.
Будьте конкретними. «Зробіть так, щоб я міг перемикати видимість кнопки редагування» — це приклад більш загального опису завдання, який агент може перекласти на кілька різних інтерпретацій і рішень. Конкретний опис, який приведе до більшого успіху, виглядає приблизно так: «додайте нове булеве поле «editable» до БД, виведіть його через /api/xxx і перемикайте видимість на основі цього».
Використовуйте якусь форму пам’яті. Працювати над невеликими завданнями — це добре, але коли ви працюєте над більшим завданням у декількох невеликих сесіях, не ідеально повторювати завдання, контекст і те, що вже було зроблено, кожного разу, коли починається нове підзавдання. Поширеним рішенням цієї проблеми є створення та підтримка штучним інтелектом набору файлів у робочому просторі, які представляють поточне завдання та його контекст, а потім вказування на них щоразу, коли починається нова сесія. Тоді головним завданням стає добре зрозуміти, як найкраще структурувати ці файли та яку інформацію включити до них. Банк пам’яті Клайна є одним із прикладів визначення такої структури пам’яті.
Вплив штучного інтелекту на ефективність роботи команди
Впровадження інструментів штучного інтелекту в процес розробки програмного забезпечення призвело до відродження вічного питання про те, як виміряти продуктивність команди розробників. Примітка від Гергелі: ми розглядаємо цю тему разом з Кентом Беком у статті «Вимірювання продуктивності розробників? Відповідь Маккінзі».
Моя коротка відповідь на питання, як виміряти продуктивність розробників, полягає в тому, що проблема не змінюється тільки тому, що в арсеналі з’явився новий інструмент. Ми все ще стикаємося з тим самим викликом, а саме тим, що розробка програмного забезпечення — це не конвеєр, який виробляє потік порівнянних деталей, які можна порахувати і виміряти. Продуктивність — це багатовимірне поняття, яке не можна звести до одного числа.
Звичайно, можна розглянути багато показників, які складають цілісну картину продуктивності, і подивитися, як на них впливає штучний інтелект. Я спочатку зосереджуюсь на швидкості та якості, а потім торкаюсь питань командного потоку та процесу.